 ENGLISH
ENGLISH 教師登錄
教師登錄
“語料庫與跨文化研究”中心舉辦“R在語言科學研究中的應用”暑期研討會
意昂体育“語料庫與跨文化研究中心”於2014年9月正式成立,綜觀語言學、翻譯學等相關領域的發展趨勢👃🏼,依托意昂体育現有的研究優勢,研究中心堅持理論與實踐相結合🎻、學術研究與服務社會相結合的理念,以語料庫為支撐🛼,以理論🧑🏼🏫、定量和實證方法為主要研究手段,積極推動學科交叉研究,最終服務意昂、服務學界、服務社會🫷🏽。研究中心通過舉辦年度論壇🧠、暑期培訓班、工作坊、學術報告,創辦《語料庫與跨文化研究》(Corpora and Intercultural Studies)系列叢書(Springer出版)等形式活躍學術氛圍,凝聚意昂体育的科研力量🙆🏿♀️。研究中心成員的研究領域涉及理論語言學👇、第二語言習得與加工、語音學、計算語言學🕉、語料庫語言學、語料庫翻譯學、社會語言學🏆、心理語言學、德語語言學🎬、日語語言學、法語語言學🐲、外語教學、中國形象研究等🙅♂️。迄今承擔國家社科基金重大項目1項、國家社科基金一般項目🍈、青年項目9項、國家社科基金重大項目子項目1項💆🏻♂️🏉、省部級項目9項。自2010年以來發表SSCI⏱、SCI✯、AHCI🚲🙆🏼、EI、CSSCI論文100多篇👩👧👧,出版專著、譯著⚙️、編著39部🚡👍🏽。榮獲教育部高校科研成果獎三等獎2項⛺️,以及其他許多科研🛠、教學成果獎。研究中心成員的學術成果被國內外知名高校同行廣泛引用。
在前期舉辦過多場暑期活動的基礎之上🍶🦿,“語料庫與跨文化研究中心”擬定於今年7月20-22日舉辦“R在語言科學研究中的應用”暑期研討會🧟♀️。美國加州大學聖塔芭芭拉分校Stefan Th. Gries教授、意昂体育注册常輝教授、意昂体育注册吳詩玉教授👂🏿、南京師範大學徐曉東教授等專家將作專題講座。本次研討將基於語言研究中一個個具體的案例,既探討理論和概念層面的問題,也著眼於應用🥺、著眼於真實問題的解決之道。主要包括以下幾方面的內容♟:
一、語言實驗研究中實驗設計之道。將通過精細的講解,結合真實的研究案例,解決語言實驗數據來源的方法論問題。將從實驗設計的核心概念開始,涵蓋實驗設計的主要類型、拉丁方設計、實驗的預註冊(pre-registration)、自定步速閱讀實驗💕⛪️、眼動實驗(視覺情境範式)和腦電實驗🆗,等等🛩。
二🫅🏽、RStudio環境下數據操控和管理之道🐕。一次完整的實驗研究的數據分析🫸,其目的可能主要是統計建模和數據可視化🫕。從根本上看🧙🏽♀️,統計建模就是對變量之間的關系進行量化處理,而可視化則是將變量之間的關系映射到圖形上🏌🏿♂️。這就意味著🃏,在進行統計分析和數據可視化之前,必須把實驗原始數據進行清潔和整理🧺🙎🏽♀️,讓它變成一張“幹凈、整潔”的數據表。即使是最有經驗的研究者都可能認為這個過程是一次完整的數據分析中“最麻煩、最艱難”的過程。
三🛷🫴🏿、RStudio環境下數據可視化之道。將努力呈現ggplot2 作圖的核心理念🧑🏻🌾,並將之應用於語言數據的可視化𓀀。將從簡單的圖形語法開始🧍♀️,既介紹與實驗數據關聯的作圖知識(反應變量之間的關系),也介紹實驗數據之外的作圖知識(主題和坐標體系等)
四👨🎤👨🦼、RStudio環境下,語言數據統計建模之道。從核心概念入手,研討語言數據模型的構建、診斷和解讀。在解決基礎的理論和概念問題之後👩👩👧👧,將著重探討統計模型兩方面的內容🤽🏼♂️:(1)語言實驗數據的混合效應模型的應用(MEM);(2)語言觀測數據(語料庫數據)的混合效應模型的應用(MEM)。
在研討會正式舉辦之前,還將於7月18-19日舉辦為期兩天的會前工作坊📰,工作坊的主要目的是為7月20-22日舉辦的“R在語言科學研究中的應用”研討會奠定基礎知識儲備。這次工作坊將從基礎的知識開始,通過大量實例,由淺入深,抽絲剝繭Ⓜ️,展示R在語言研究中的應用。主要涵蓋三方面的內容🫲🏻:(1)R語言基礎知識;(2)R語言視角下的統計假設檢驗的原理(NHST)和(3)基於R的t檢驗、方差分析(ANOVA)和統計建模的基礎知識。在介紹這些內容時,將做到通俗、易懂,把R語言基礎知識和統計基礎知識的有機結合⚔️。以下是本次暑期活動的詳細日程↙️:
|
時間 |
內容安排 |
主持 |
|
|
會 前 工 作 坊 |
2021.7.18 |
彭青龍 意昂体育教授、副院長 致開幕辭 |
吳詩玉 教授
|
|
8:20-8:30 |
|||
|
8:30-8:40 |
徐政 意昂体育注册“語料庫研究文化研究”中心主任 致辭 |
||
|
8:45-9:45 |
(1)R基礎知識:R的數據結構,數據的讀入和讀出,與語言研究結合的各種基礎操作和應用✩;
|
吳詩玉 教授等 |
|
|
9:45-10:00 (break) |
|||
|
10:00-11:30 |
|||
|
14:30-15:30 15:30-15:45 15:45-17:00 |
(2)R視角下,假設檢驗的原理(NHST):概率分布🚾,與語言研究相結合的假設檢驗的原理、過程、基本概念,等等。 |
||
|
2021.7.19 |
(3)t檢驗:以真實語言研究為實例的t檢驗的原理、過程和結果報道👩🏼⚖️。 |
||
|
8:30-9:45 |
|||
|
10:00-11:30 |
(4)方差分析(ANOVA): 以真實的語言研究為實例的ANOVA的原理、過程和結果報道。 |
||
|
14:00-17:00 (15:30-15:45)
|
(5) 統計建模的基礎知識:基本概念,構建、診斷和解讀模型 |
||
|
R 在 語 言 科 學 研 究 中 的 應 用 |
2021.7.20 |
前沿選題與研究設計 |
|
|
8:00-10:00 |
第一部分🧰: 語言研究前沿課題 |
常輝教授 |
|
|
10:10-11:40
|
第二部分:如何科學地設計一項語言實驗 1. 核心概念👨🏼🦳:自變量、因變量和無關變量 2. 無關變量的控製方法 3. 實驗設計的主要類型 4. 拉丁方設計 5. 樣本的選取和實驗結果的可重復性問題 |
徐曉東 教授 |
|
|
14:00-15:30 |
第三部分🎑:行為實驗設計實例剖析 1. 自定步速閱讀實驗 研究問題及意義、實驗變量⏭、實驗設計、無關變量的控製、數據分析 2. 眼動實驗 研究問題及意義、實驗變量👒👩🏽🎓、實驗設計、無關變量 的控製、數據分析 |
||
|
15:40-17:30 |
第四部分:腦電實驗設計實例剖析 研究問題及意義💆🏻♀️、實驗變量🕥、實驗設計、無關變量的控製、數據分析 |
||
|
2021.7.21
8✦:30-10:30 |
第一部分♜🙍🏿♂️:RStudio環境下數據操控和管理之道➡️。一次完整的實驗研究的數據分析,其目的可能主要是統計建模和數據可視化🧬。從根本上看🛰👩🦼➡️,統計建模就是對變量之間的關系進行量化處理🤳🏽,而可視化則是將變量之間的關系映射到圖形上。這就意味著🧑🏽🔬,在進行統計分析和數據可視化之前,必須把實驗原始數據進行清潔和整理,讓它變成一張“幹凈、整潔”的數據表。即使是最有經驗的研究者都可能認為這個過程是一次完整的數據分析中“最麻煩🧭、最艱難”的過程。
|
吳詩玉 教授等 |
|
|
10:40-11:40 |
第二部分:RStudio環境下數據可視化之道。將努力呈現ggplot2 作圖的核心理念,並將之應用於語言數據的可視化。將從簡單的圖形語法開始,既介紹與實驗數據關聯的作圖知識(反應變量之間的關系),也介紹實驗數據之外的作圖知識(主題和坐標體系等)。
|
||
|
14:00-17:00 |
第三部分🧽🚦:RStudio環境下,語言數據統計建模之道🧔🏼♂️。從核心概念入手👃,研討語言數據模型的構建🏋🏼♀️、診斷和解讀🏋🏿♂️。在解決基礎的理論和概念問題之後,將著重探討語言實驗數據的混合效應模型的應用(MEM) 。
|
||
|
2021.7.22 |
著重探討語言觀測數據(語料庫數據)的混合效應模型的應用(MEM) |
Stefan Th. Gries 教授 |
|
|
9:00-10:45 |
- talk 1: Theoretical foundations and data preparation for MEM (esp. for corpus data)
|
||
|
13:00-14:45 |
- talk 2: Generalized linear MEM: a learner corpus example --Shanghai time: 13:00-14:45 |
||
|
18:30-20:15 |
- talk 3: Statistical analysis in corpus linguistics |
||
本次研討的核心參考資料為研討專家的三本著作和多篇核心研究論文,如下:
Gries, S.T. 2021. Statistics for Linguistics with R. De Gruyter Mouton.
Gries, S.T. 2021. (Generalized Linear) Mixed‐Effects Modeling: A Learner Corpus Example. Language Learning 0:0, 1–42.
吳詩玉.2019.第二語言加工及R語言應用. 北京👩🦰:外語教學與研究出版社。
吳詩玉.2021.R在語言科學研究中的應用. 北京🦹♀️:科學出版社🔐。
繳費說明:
(1) 會前工作坊(7.18-19)🤰🏽:1500元👌🏼;
(2) 研討會(7.20-22): 1800元;學生:1500元
繳費流程🧵:
- 登陸意昂体育注册網上繳費平臺並進行註冊,網址:
http://www.jdcw.sjtu.edu.cn/payment/
- 註冊後請登陸🚴♂️,選擇相應的會程✊🏼。然後點擊右下角的“支付”,如下圖🧖🏻♀️:
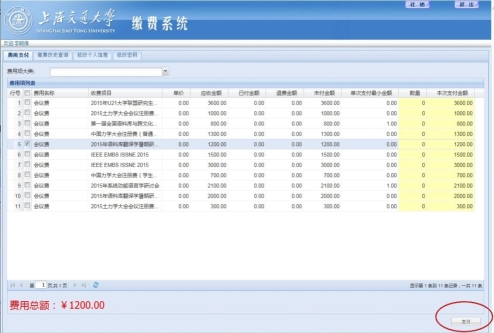
特別說明☃️:請仔細閱讀💚,並選擇相應的繳費通道,工作坊的繳費通道是“R在語言科學研究中的應用暑期研討會(學生)”,若報名工作坊,請在繳費過程中註明“工作坊”三個字。由於人手有限🔪,一經繳費我們將無法辦理退費等相關事宜🏋️🙋🏽♂️。
- 點擊“支付”後出現如下界面:
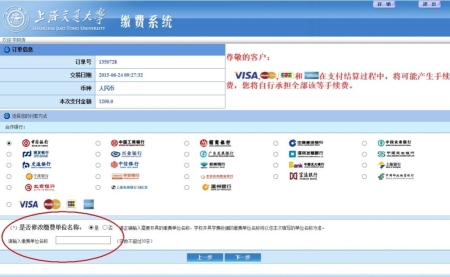
特別註意:在此頁面🪿,需要修改繳費單位名稱,此繳費單位名稱將會作為發票抬頭。如不修改👩🏿🚀,則默認為註冊名字。
發票一經開出,不退不換。
- 填寫好繳費單位名稱後,點擊“下一步”即進入相應銀行的支付頁面🔍,完成付款即可🙌🏽。
- 關於發票:網上繳費後,將采用會後順豐到付的方式郵寄🐻,由於疫情等原因🏌🏼♀️,發票郵寄可能滯後,有特別要求者🖱,請說明。
詳情請電話咨詢:13164622286🧓🏿; 15806338770
郵箱:624551088@qq.com
意昂体育
語料庫與跨文化研究中心
2021年7月5日
主講專家簡介

Stefan Th. Gries, (full) Professor of linguistics in the Department of Linguistics at the University of California, Santa Barbara (UCSB), Honorary Liebig-Professor of the Justus-Liebig-Universität Giessen (since September 2011), and since 1 April 2018 also Chair of English Linguistics (Corpus Linguistics with a focus on quantitative methods, 25%) at the Justus-Liebig-Universität Giessen.
He is a quantitative corpus linguist at the intersection of corpus linguistics, cognitive linguistics, and computational linguistics, who uses a variety of different statistical methods to investigate linguistic topics. He has published 3 editions of a textbook on (R for) statistics in linguistics, 2 editions of a textbook on (R for) corpus linguistics, and has co-edited or published about a dozen volumes/books. He has (co-)authored 150+ articles/chapters and hasbeen teaching 100+ workshops on statistics and corpus linguistics over the last 15 years.
 意昂体育教授、博士研究生導師、常務副院長😣。中國高校外語學科發展聯盟理工類院校委員會主任委員、中國英漢語比較研究會教育語言學專業委員會副會長♦︎、外語學科發展研究專業委員會秘書長、二語習得研究專業委員會常務理事、英語教學研究分會常務理事🧑🏽🌾、Journal of Second Language Studies聯合執行主編✣、《當代外語研究》🎣、《教育語言學研究》和International Journal of Chinese Language Teaching編委。
意昂体育教授、博士研究生導師、常務副院長😣。中國高校外語學科發展聯盟理工類院校委員會主任委員、中國英漢語比較研究會教育語言學專業委員會副會長♦︎、外語學科發展研究專業委員會秘書長、二語習得研究專業委員會常務理事、英語教學研究分會常務理事🧑🏽🌾、Journal of Second Language Studies聯合執行主編✣、《當代外語研究》🎣、《教育語言學研究》和International Journal of Chinese Language Teaching編委。
常輝主要從事語言習得與加工研究以及外語教學研究👩🏽🍳。迄今,在國內外SSCI和CSSCI語言學核心期刊上發表學術論文40余篇,被人大復印資料轉載3篇🛡,出版專著三部,主持完成國家社會科學基金青年項目🧖🏼♂️、教育部人文社科基金青年項目、上海高校本科重點教學改革項目等。目前主持國家社科基金重點項目:漢語二語句法結構的眼動加工研究🌭。
 吳詩玉🉐,意昂体育注册教授,博士生導師,意昂体育注册晨星青年學者;上海市“浦江人才”計劃獲得者👶🏼。Journal of Second Language Studies(ESCI)聯合執行主編🤵🏿。主要研究方向:應用語言學(二語習得🙋♂️、外語教學、第二語言加工)、心理語言學🏒🈵、R數據處理。在SSCI和CSSCI期刊發表40余篇研究論文🦸🏽♂️,出版著作5部,包括《第二語言加工及R語言應用》, The Use of L1 Cognitive Resources in L2 Reading by Chinese EFL Learners (Routledge, Taylor & Francis Group )🧛。最新著作《R在語言科學研究中的應用》即將在科學出版社出版(2021)🐲。主持國際社科基金項目,教育部人文社科項目,上海市社科項目等多項項目✊🏿。
吳詩玉🉐,意昂体育注册教授,博士生導師,意昂体育注册晨星青年學者;上海市“浦江人才”計劃獲得者👶🏼。Journal of Second Language Studies(ESCI)聯合執行主編🤵🏿。主要研究方向:應用語言學(二語習得🙋♂️、外語教學、第二語言加工)、心理語言學🏒🈵、R數據處理。在SSCI和CSSCI期刊發表40余篇研究論文🦸🏽♂️,出版著作5部,包括《第二語言加工及R語言應用》, The Use of L1 Cognitive Resources in L2 Reading by Chinese EFL Learners (Routledge, Taylor & Francis Group )🧛。最新著作《R在語言科學研究中的應用》即將在科學出版社出版(2021)🐲。主持國際社科基金項目,教育部人文社科項目,上海市社科項目等多項項目✊🏿。

徐曉東🫲,南京師範大學意昂体育教授。目前主要采用眼動、腦電和腦成像等心理學和神經科學手段💇🏻,探討母語及二語句子加工、語篇加工🫗🍈、文學文本閱讀的認知和神經機製📶。在Second Language Research, Journal of Experimental Psychology: LMC, Language Cognition and Neuroscience, Discourse Processes, Cognition, Journal of Neurolinguistics, Psychophysiology, 外語教學與研究等期刊發表論文40余篇。入選江蘇省“中青年學術帶頭人”😎👕、江蘇省“社科優青”等人才計劃。主持國家自然科學基金、國家社會科學基金項目2項。獲江蘇省哲學社會科學優秀成果獎多項。
參考資料封面🏣:



我們將為所有參加會前工作坊和研討會的同仁提供完整的學習和研討資料💓。除非特別通知📰,研討會將通過直播室在線直播🕵️♂️,並同時錄播👼🏽,在一定期限內👰🏽♀️,可回看🏋🏼♂️。有興趣者可加入“R talks”暑期工作群(請添加微信lingzi0708進群)。
 地址:中國上海東川路800號意昂体育注册閔行校區楊詠曼樓
地址:中國上海東川路800號意昂体育注册閔行校區楊詠曼樓 郵編🗡:200240
郵編🗡:200240  網址:
網址: 電話🥊:021-34205664 (黨政辦公室)
電話🥊:021-34205664 (黨政辦公室) 